Last semester, in course 1.202 Demand Modeling, there is an interesting case study of Quebec energy consumption. Exploratory data analysis indicates that there are potential market segments, and subsequent computation shows that multinomial logit models estimated from separate datasets have a better total log likelihood than the one from the whole dataset. An interesting question then arises: can we discover latent classes efficiently on high dimensional data?
Problem description
Assume we have $m$ customers and $n$ options. For each customer, there are personal attributes $X_{p,i}\in R^{d_1}(i\in\{1,\cdots,m\})$ and option-specific attributes $X_{o,i,j}\in R^{d_2} (i\in\{1,\cdots,m\}, j\in\{1,\cdots,n\})$. We want to estimate parameters $\beta_{j}\in R^{d_1+d_2} (j\in\{1,\cdots,n\})$ in the following choice model:
$$p(j|X_{p,i},X_{o,i,j})=\frac{\exp(\beta_j^TX_j)}{\sum_i \exp(\beta_i^TX_i)}$$
where $X_j=(X_{p,i},X_{o,i,j})$.
If we know the whole dataset comes from a single class, the estimation is simple: we use write the log likelihood function and optimize it using standard optimization package. But in many cases this might not be true.
For example, in the Quebec energy case, we observe the following:
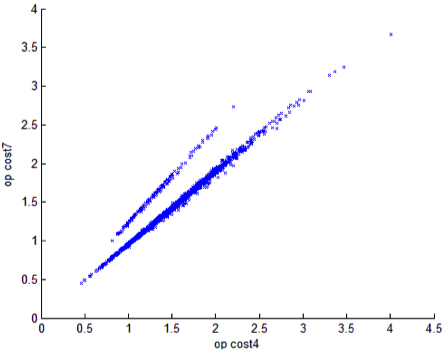
There are clearly two classes. If we separate them and plot histograms of other attributes respectively, we find that for some variables the difference is quite significant, which indicating a potential market segments.
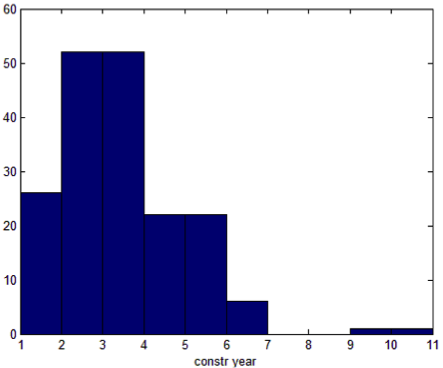
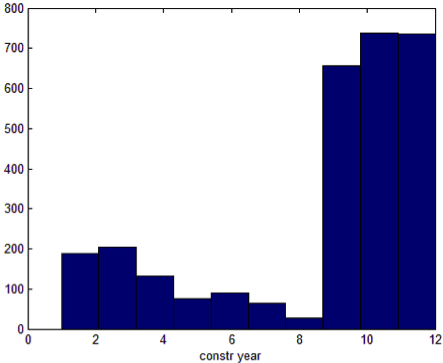
So, in more general cases, how can we discover such patterns if exploration is not always feasible? Moreover, how can we make sure our segmentation will improve the model performance?
An initial approach
Our target is to separate the dataset to improve our objective function; so why not look at the final gradients? Even though the sum of gradients will be close to 0, they might not be homogenous small and uniformly distributed. If we can find some hyperplanes to separate the dataset in such a way that the sum of gradients in each region is significant, we can then improve our estimates on each subset by driving the parameters into different directions.
As an initial approach, we will consider the simplest case: regression tree on categorical variables. In each iteration, we solve the MLE problem, obtain the gradient at each data point, and then for each categorical variable, we search for a cutoff value that best ‘separate’ the set of gradients, or, that makes the difference between the sum of two subset greatest. Finally, we compare these differences across variables and select the most influential one. We will stop once the improvement is negligible.
We implement this idea and test it on the Quebec dataset. The code can be find here. Since gradients in logit model can have great scale, we normalize them in each step to stabilize the algorithm. It is shown that the code successfully finds the variable ‘constr_year’ and the cutoff value 7. The total log likelihood improves a lot, while the segmentation is quite balance (561 v.s. 499).
Conclusion
In this small case study, we purpose a simple algorithm to find latent classes in a choice dataset. It is clear that our approach is quite limited since we only consider categorical variables and the approach to find cutoff value can be highly unstable. Nevertheless, this approach can be a good start in exploring potential segmentation and support future analysis. Next, we will try to solve the problem from another perspective: can we include latent class directly in our inference model and design efficient estimation algorithm?