在这篇文章中,我将介绍初始对偶可行基的寻找方法以及迭代过程中数值误差的处理,以进一步完善对偶单纯形法的求解流程,保障求解结果的可靠性。
第一阶段问题 The Phase 1 Problem
在前一篇文章中,我介绍了如何使用对偶单纯形法(DS)来找到一个线性规划问题的最优解。不过,要运用DS方法,首先需要有一组对偶可行的基;而对于很多问题来说,这并不是平凡(trivial)的。下面,我将介绍一种寻找对偶可行基的方法。
此前,我们考虑了以下形式的原始-对偶问题对:
$$
\begin{aligned}
\min \ & c^T x \\
s.t. \ & Ax = b, \\
& l \leq x \leq u,
\end{aligned}
\label{eq:primal}\tag{1.1}
$$ $$
\begin{aligned}
\max \ & b^T \lambda + u^T s_u + l^T s_l \\
s.t. \ & A^T \lambda + s_u + s_l = c, \\
& s_l \geq 0, \ s_u \leq 0,
\end{aligned}
\label{eq:dual}\tag{1.2}
$$ 其中上下界$l,u$的取值可以为$\pm \infty$。为了进一步分析一组解$(x,\lambda,s)$的对偶可行性,可将对偶问题\eqref{eq:dual}改写成以下形式:
$$
\begin{aligned}
\max \ & b^T \lambda + u^T s^- + l^T s^+ \\
s.t. \ & A^T \lambda + s = c, \\
& s^T I(u \geq \infty) \geq 0, \ s^T I(l \leq -\infty) \leq 0.
\end{aligned}
\label{eq:dual_extend}\tag{1.3}
$$ 其中,最后一行中的新增两个约束的意义是:如果某个$u_j \geq \infty$,则相应的$s_j$必须不小于0;如果某个$l_j \leq -\infty$,则相应的$s_j$必须不大于0。特别地,如果所有变量的上下界都是有限值,那么这两个约束是trivial的;在此情况下,对任意一个狭义基$B$,可以找到一组$(L,U)$使得相应的解$(x,\lambda,s)$是对偶可行的。
接下来,对一组满足约束$A^T\lambda + s = c$的对偶解$(\lambda,s)$,其相对于问题\eqref{eq:dual_extend}的不可行程度可以表示为
$$
z_{inf} = -(s^-)^T I(u \geq \infty) + (s^+)^T I(l \leq -\infty); \label{eq:dual_infeas}\tag{1.4}
$$ 因此,对偶问题\eqref{eq:dual_extend}存在一组可行解,当且仅当以下问题的最优目标值为0:
$$
\begin{aligned}
\max \ & - z_{inf} = (s^-)^T I(u \geq \infty) - (s^+)^T I(l \leq -\infty) \\
s.t. \ & A^T \lambda + s = c.
\end{aligned}\label{eq:dual_extend_infeas}\tag{1.5}
$$ 进一步来说,如果问题\eqref{eq:dual_extend_infeas}的最优目标值为0,则任一组最优解$(\lambda,s)$都是原对偶问题\eqref{eq:dual_extend}的可行解。又通过比较问题\eqref{eq:dual_extend}和\eqref{eq:dual_extend_infeas}的形式可以发现,问题\eqref{eq:dual_extend_infeas}正好是以下原始问题所对应的对偶问题:
$$
\begin{aligned}
\min \ & c^T x \\
s.t. \ & Ax = 0; \\
& -I(l \leq -\infty) \leq x \leq I(u \geq \infty). \\
\end{aligned}\label{eq:primal_phase1}\tag{1.6}
$$ 因此,可以考虑以下求解流程:先通过DS求解问题\eqref{eq:primal_phase1}来获得原问题\eqref{eq:primal}和\eqref{eq:dual_extend}的一组对偶可行基,然后再从这组基出发,通过DS求解原问题\eqref{eq:primal}的最优解。由于问题\eqref{eq:primal_phase1}中所有变量的上下界都是有限值,根据前述讨论,任意狭义基$B$都是对偶可行的,故寻找问题\eqref{eq:primal_phase1}(以及整个求解流程)的初始对偶可行基是trivial的。
Koberstein and Suhl (2007)通过数值实验验证了上述思路(他们称之为SP)的有效性。由于这种方法只需要复用已有的DS流程的代码,开发起来较为简便,因此在本系列中我仅考虑了该方法的实现。一些其他的Phase 1思路可以参见Koberstein and Suhl (2007)以及A. Koberstein论文的第4章。
数值误差处理 Numerical Issues
根据前一个notebook中的测试结果,在前一篇文章中介绍的DS算法存在以下问题:(1)迭代步中对可行性的判断可能错误,导致求解过程过早中止;(2)矩阵$A_B$的条件数(condition number)可能变得很大,甚至矩阵变成奇异的(singular),导致求解过程无法继续。这些问题都可以归结于(求解过程中产生的)数值误差没有得到合适的处理。下面,我将介绍DS算法中数值误差的主要产生原因和解决方法。
在一次DS迭代的计算中,最容易产生数值误差的部分是线性方程求解。根据线性代数知识,线性方程求解所产生的误差大小与矩阵$A_B$的条件数有直接关系:条件数越大,求解误差越大。因此,要降低线性方程求解所带来的数值误差,需要对$A_B$的条件数进行控制。我首先来分析一次DS迭代对$A_B$的条件数的影响。不妨假设在一次迭代后,矩阵$A_B$的第$i_B$列$A_i$被$A$的第$j$列$A_j$代替,并将代替后的矩阵记为$A_{B’}$。直观来看,如果$A_j$与$A_B$中除了$A_i$的其他$n-1$列的线性相关性非常强,甚至可以被这些列线性表示,那么$A_{B’}$会非常接近singular。又根据线性代数知识,向量$A_B^{-1}A_j$代表了用$A_B$的列对$A_j$进行线性表示的结果;因此,可以推断:如果值$\delta s_j = e_i^T[A_B^{-1}A_j]$很小,那么$A_{B’}$的条件数相比$A_B$会有很大的增长。事实上,可以证明以下不等式:
$$
cond(A_{B’}) \leq \frac{1}{|\delta s_j|} \cdot (1 + \Vert A_B^{-1}A_j \Vert) \cdot (1 + \|A_B^{-1}A_j\| + |\delta s_j|) \cdot cond(B). \tag{2.1}
$$ 因此,在ratio test阶段,应尽量避免选择$|\delta s_j|$很小的列$j$来进入$B$。
然而,即使每步DS迭代的ratio test阶段都选择了$|\delta s_j|$较大的列$j$,我们仍然无法保证在多次迭代后$A_B$的条件数维持在一个合理的范围内。从整个算法流程的角度来看,DS迭代过程相当于从一组基出发,沿着一条邻接路径(path)前进,试图抵达最优基;通过优化ratio test阶段的决策,只能降低路径上相邻基的条件数发生突变的可能性,而不能保证整条迭代路径完全不经过高条件数的区域。考虑到通常很难预判这一问题的出现,在本系列的实现中,我将考虑下面的事后(ex-post)处理策略:一旦迭代路径进入高条件数区域并无法继续前进,那么回滚(rollback)迭代过程到一个低条件数区域,并尝试对问题进行随机扰动来切换路径方向。根据数值实验,对于大多数问题,少数几次随机扰动就能够使迭代路径避开高条件数区域了。
另外,随着迭代次数的增长,为了提高计算效率所引入的线性方程求解优化技巧(PFI、LU update等)所产生的数值误差也会逐渐累积。因此,一方面,需要在迭代过程中对数值误差进行监控,并及时进行矩阵分解处理;另一方面,考虑到数值误差可能无法避免,需要引入容忍度(tolerance),并结合问题的理论性质来保证各阶段计算结果的可靠性。
接下来,我将进一步介绍上述各种数值误差处理方法的实现细节。
Robust Ratio Test
ratio test阶段的主要任务是根据对偶变量$s$和单位变化量$\delta s$选择合适的列$j$和对偶步长$\alpha_{dual} \geq 0$。不妨假设求解过程中的对偶可行性容忍度(tolrance)设置为$\varepsilon_{dual}$,pivot tolerance为$\varepsilon_{pivot}$。基于上一篇blog中的内容及上面关于数值稳定性的讨论,在ratio test阶段需要考虑以下几个目标:
- 保持(在容忍度内的)对偶可行性:
$$s’ = s + \alpha_{dual} \delta s; \ s’_{L’} \geq -\varepsilon_{dual}, \ s’_{U’} \leq \varepsilon_{dual}; \tag{2.2}$$ - 被选中列$j$对应的pivot值$|\delta s_j|$不应过小:$|\delta s_j| \geq \varepsilon_{pivot}$;
- 优化对偶目标值:在可行范围内尽可能扩大对偶步长$\alpha_{dual}$。
下面逐个目标进行讨论。首先,我将分析对偶步长对对偶可行性的影响。不妨假设对偶步长$\alpha_{dual}$已给定。对于每个下标/列$j\in L\cup U$,
- 如果$s_j$与$\delta s_j$符号相反,那么当$\alpha_{dual}$取值变化时,$s’_j$的符号可能与$s_j$相反:
- 首先,计算“临界对偶步长”$\alpha_j = -s_j/\delta s_j$:在此步长下,$s’_j = s_j + \alpha_j \delta s_j = 0$;
- 当$\alpha_{dual}$大于$\alpha_j^+ = \alpha_j + \varepsilon_{dual}/|\delta s_j|$时,$s’_j$与$s_j$符号相反且$|s’_j| \geq \varepsilon_{dual}$,因此需要翻转$j$的类型才能保证对偶可行性;
- 当$\alpha_{dual}$小于$\alpha_j^- = \alpha_j - \varepsilon_{dual}/|\delta s_j|$时,$s’_j$与$s_j$符号相同且$|s’_j| \geq \varepsilon_{dual}$,因此需要保持$j$的类型来保证对偶可行性;
- 当$\alpha_{dual} \in [\alpha_j^-,\alpha_j^+]$时,$|s’_j| \leq \varepsilon_{dual}$,此时无论是保持还是翻转$j$的类型都不影响对偶可行性。
- 如果$s_j$与$\delta s_j$符号相同,那么$s’_j$也一定与$s_j$符号相同:
- 令“临界对偶步长”$\alpha_j$为$\infty$;
- 需要保持$j$的类型来保证对偶可行性。
其次,我将分析对偶步长对对偶目标值和梯度的影响。根据上述讨论,对于一个给定的对偶步长$\alpha_{dual} \geq 0$,可以计算出为了保持对偶可行性所必须要翻转的所有下标的集合$\mathcal{J}_{flip}$。又根据上一篇blog中的内容,每翻转一个下标$j$的类型,对偶梯度会下降$(u_j - l_j) |\delta s_j|$;因此,翻转所有下标后的对偶梯度为$\Delta x_i - \sum_{j\in\mathcal{J}_{flip}} (u_j - l_j) |\delta s_j|$。由于集合$\mathcal{J}_{flip}$是随$\alpha_{dual}$单调递增的,而初始的对偶梯度$\Delta x_i > 0$,因此可以不断扩大对偶步长$\alpha_{dual}$来优化对偶目标值,直到对应的对偶梯度小于0。不妨记该临界对偶步长和相应的下标为$\alpha_{dual}^+=\alpha_{j^+}^+$和$j^+$,并以此作为最终选取的对偶步长$\alpha_{dual}$的上界。$\alpha_{dual}^+$的取值可以通过二分法的方式确定,也可以通过对$\alpha_j^+$进行排序、然后做线搜索确定,但后者的时间复杂度是$O(n\log n)$,在大多数场景下效率更低。
接下来,需要选择一个列$j_*$,使得对偶步长$\alpha_{dual} = \alpha_j < \alpha_{dual}^+$尽可能大的同时,值$|\delta s_j|$尽可能高于阈值$\varepsilon_{pivot}$。注意到$|\delta s_j|$的大小对应区间$[\alpha_j^-,\alpha_j^+]$的宽度,一种简单的选法是从所有满足$\alpha_j < \alpha_{dual}^+$的列中选取$\alpha_j^-$最大的一个。这种做法的问题在于,即使在临界范围$|\delta s_j| \approx \varepsilon_{pivot}$,区间宽度$2\varepsilon_{dual}/|\delta s_j|$的量级相比$\alpha_j$仍小不少,因此最后选中的$|\delta s_{j_*}|$可能还是很小。在本系列的实现中,我考虑了另一种简单思路:从所有$\alpha_j$落在区间$[\alpha_{j^+},\alpha_{dual}^+)$的列$j$中,选出$|\delta s_j|$最大的一个:
$$j_* = \arg\max_{j\in \{ j|\alpha_j \in [\alpha_{j^+},\alpha_{dual}^+) \} } |\delta s_j|. \tag{2.3}
$$ 这种选取方式通过将对对偶步长的要求从优化目标转为约束,能够一定程度上提高最后的$|\delta s_{j_*}|$的大小;同时,该方法还能够保证$j^+$是一个可选选项。
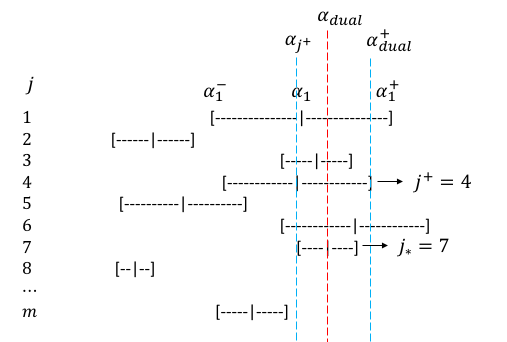
下面,我将通过一个例子来进一步解释上面的流程。下图展示了一个ratio test问题,其中每个列对应的区间为$[\alpha_j^-,\alpha_j^+]$。不妨假设已有$j^+ = 4$。在所有满足$\alpha_j < \alpha_{dual}^+$的列$j$中,列$j=6$对应的对偶步长$\alpha_j$最大,但是其区间宽度也较大,意味着$|\delta s_j|$比较小。若按代码中实现的选取方法,则先选出区间$[\alpha_{j^+},\alpha_{dual}^+)$覆盖的列$\{1,3,4,6,7\}$,然后从中选出区间宽度最小的一个$j=7$。在此例子中,$j=7$恰好也对应$\alpha_j^-$最大的列,故上述两种选择方法等价。
有些时候,按照上述流程所确定的对偶步长$\alpha_{dual}$会很小;一种可能的原因是随着迭代次数增加,数值误差积累,导致对偶变量的取值非常接近容忍度$\varepsilon_{dual}$。在这种情况下,当前DS迭代步难以取得进展,甚至可能陷入死循环(cycling)中。一种有效的解决方法是扩大对偶步长至某个阈值,并对原问题的目标系数$c$进行偏移(shift)来恢复对偶变量的可行性(注意到对偶变量$s = c - A^T\lambda$)。在大多数情况下,做shift能够有效提高数值稳定性,但是可能会导致DS的最终结果对于原问题是对偶不可行的,因此需要在DS流程结束后引入primal simplex(PS)迭代(一般只需少数几次迭代即可)。
随机扰动 Random Perturbation
在各种教材和文献中,随机扰动(perturbation)一般被认为是用来缓解退化(degeneracy)现象的。对于DS迭代过程,degeneracy指存在下标$j\in L\cup U$使得$s_j = 0$;这会导致当前迭代步的对偶步长为0,而且如果ratio test阶段选择了不合适的下标,迭代过程可能会进入死循环(cycling)。虽然历史上人们提出了多种degeneracy的处理方法,但目前看来,逻辑最为简单的手段是结合perturb和shift。关于degeneracy的更多讨论可以参考A. Koberstein论文的第6章。
除了缓解degeneracy外,随机扰动还能起到调整DS迭代路径的作用。具体来说,在ratio test阶段,下标的选择同时受到对偶变量$s$和单位变化量$\delta s$的影响;如果对$c$进行随机扰动,则各$s_j/\delta s_j$的相对大小会有所变化,因此迭代方向在一定几率上会被改变。当然,我们无法保证随机扰动后迭代路径一定会变“好”,因此在求解流程中可能需要进行多次随机扰动,一定程度上会影响求解效率。
在设计随机扰动方案时,首先需要确定扰动对象。一个LP问题的主要元素包括矩阵$A$、约束向量$b$、目标向量$c$、以及上下界$u,l$。扰动$A$会影响可行域的结构,有可能导致扰动后的最优解离真实的最优解较远,反而降低了整体求解效率。扰动上下界$u,l$只会对原始可行域进行缩放,一般不会对DS迭代过程有显著影响。扰动$b$和$c$在DS迭代中分别影响pricing和ratio test阶段;根据上面对随机扰动作用的分析,对$c$进行扰动更符合我们的预期目标。
其次,需要考虑具体的扰动方式。由于随机扰动的一个目标是让问题变得更容易求解,故应尽量将问题朝更对偶可行的方向扰动。具体来说,如果上界$u_j \geq \infty$,那么应避免出现$s_j < 0$,故应将$c_j$向上扰动;如果下界$l_j \leq -\infty$,那么应避免$s_j > 0$,故应将$c_j$向下扰动;如果上下界都无界,可以不做扰动(free变量一般一直在$B$中,不会对迭代路径产生影响);而如果上下界都是有限值,则扰动方向可以任意选取。
在实际实现中,大多数求解器会考虑一些其他因素以提升随机扰动的效果。有兴趣的读者可以进一步参考A. Koberstein论文的第6.3节。
误差检测 Error Detection
上面提到,有必要在迭代过程中对数值误差进行监控,以及时进行LU重分解来提高数值精度。下面,我将介绍几种常用的误差检测方法。
首先,由于解$(x,\lambda,s)$是基于基$(B,L,U)$的,理论上线性约束
$$A x = b, \ A^T \lambda + s = c \tag{2.4}
$$ 总是成立的;因此可以考虑监控以下误差指标:
$$\epsilon_{primal \ con} = \Vert A x - b\Vert _{\infty}, \ \epsilon_{dual \ con} = \Vert A^T \lambda + s - c\Vert _{\infty}; \tag{2.5}
$$ 一旦$\epsilon_{primal \ con}$或者$\epsilon_{dual \ con}$超过某个阈值,则应触发LU重分解操作。
然而,引入以上两个监控指标会各新增一次矩阵乘法操作,一定程度上影响了DS迭代的效率,在本系列的实现中暂不考虑。通过在已有计算结果中寻找理论等价关系并建立误差指标,可以显著节省误差检测阶段的计算开销。具体来说,
- 注意到$\delta s_0 = A^T A_B^{-T} e_i$以及$\delta x_B = A_B^{-1} A_j$,故以下等式成立:
$$(\delta s_0)_j = e_i^T A_B^{-1}A_j = (\delta x_B)_{i}, \tag{2.6}
$$ 因此可以考虑误差指标$| (\delta s_0)_j - (\delta x_B)_{i} |$。 - 同样根据$\delta s_0$的定义,有
$$(\delta s_0)_i = e_i^T A_B^{-1}A_B e_i = 1, \tag{2.7}
$$ 因此可以考虑误差指标$| (\delta s_0)_i - 1 |$。 - 第1点关注的是不变量$e_i^T A_B^{-1}A_j$,而该量只是向量$A_B^{-1}A_j$的一个元素;要进一步分析向量$A_B^{-1}A_j$的整体准确性,可以考虑不变量$c_B^T A_B^{-1}A_j$:
$$ \lambda^T A_j = c_B^T A_B^{-1} A_j = c_B^T \delta x_B; \tag{2.8}
$$ 不过引入该指标同样会引入较大的计算量,在本系列的实现中暂不考虑。 - 注意到DSE权重定义为$\beta_j = |A_B^{-T}e_j|_2^2$,而单位对偶变化量$\delta\lambda_0 = A_B^{-T}e_i$,因此可以通过比较迭代值$\beta_{i_B}$和真实值$(\delta\lambda_0)^T (\delta\lambda_0)$的一致性来检测数值误差。但是由于直接计算DSE权重的开销非常大,迭代过程中它不会经常被更新,故指标$|\beta_{i_B} - (\delta\lambda_0)^T (\delta\lambda_0)|$的值通常会比较大;因此,在本系列的实现中,该指标只是用来作为误差监控的一部分,而不用来触发LU重分解操作。
接下来,我将在代码实现中尝试将上述各技术进行整合。